
获取dom元素的几种方式
- 按使用频率排序
- 低版本浏览器 === < IE8
1.document.getElementById
简介
通过元素的id获取
- 存在 -- 则返回这个元素
- 不存在 -- 返回
null
特点
- 如果文档中存在多个相同的id,则获取第一个
- 在一些低版本浏览器会把元素的name当做id获取
- 上下文只能是
document
2.document.getElementsByClassName
简介
通过元素的类名获取
- 存在 -- 返回由目标元素组成的
HTMLCollectio - 不存在 -- 返回一个空的
HTMLCollectioHTMLCollectio是类数组
特点
- 获取的结果是一个
类数组 - 上下文可以是
任意元素(document或其它dom元素) - 在一些低版本浏览器不支持
3.document.querySelector
简介
通过选择器获取一个元素
特点
- 上下文可以是
任意元素(document或其它dom元素) - 低版本浏览器不兼容
- 返回值是类数组
4.document.querySelectorAll
简介
通过选择器获取一组元素
特点
- 同querySelector
5.document.getElementsByTagName
简介
通过标签名获取
特点
- 上下文可以是
任意元素(document或其它dom元素) - 返回值是类数组
- 参数是标签名,不区分大小写
6.document.getElementsByName
简介
通过元素的name属性获取
特点
- 上下文只能是
document - 返回值是类数组
- 在IE浏览器中只能获取到表单元素,当然我们一般也只用它获取表单元素,从ie10开始可以不只是表单元素
7.document.body
获取body这个元素
8.document.documentElement
获取html这个元素
9.document.getElementsByTagNameNS
返回带有指定名称和命名空间的所有元素的 NodeList
js
nodeList = document.getElementsByTagNameNS(namespace, name)说实话,这个API目前在我的学习/工作中还没找到落地之处😢😢
元素之间的继承关系
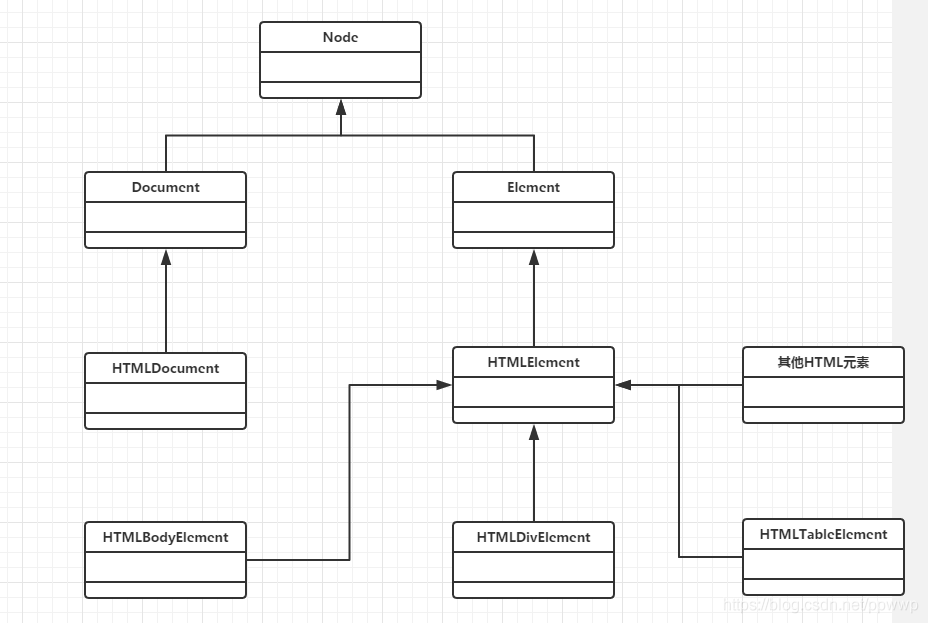
每个元素都有对应的类,因此每个类都提供了一些方法来操作元素本身
通过类之间的继承关系,丰富元素的可操作性
由于getElementById与getElementsByName方法是在Document类上,于是普通元素的实例对象是没有这两方法的,所以这两方法的上下文只能是document
总结
- 上下文只能是
document的方法- getElementById
- getElementsByName
- 上下文为
任意元素的方法- getElementsByClassName
- getElementById
- querySelectorAll
- getElementsByTagName
- getElementsByTagNameNS
- 查询效率最高的是
- getElementById:由于id在正常情况下是独一无二的,所以查询是很高效的
- 返回值
- 只有
getElementById与getElementById返回对象本身 - 其余查询方法均返回一个类数组
HTMLCollectio
- 只有